
cs230_lec6_C5W1
Updated:
Recurrent Neural Network
Sequence data란??
- 예시들
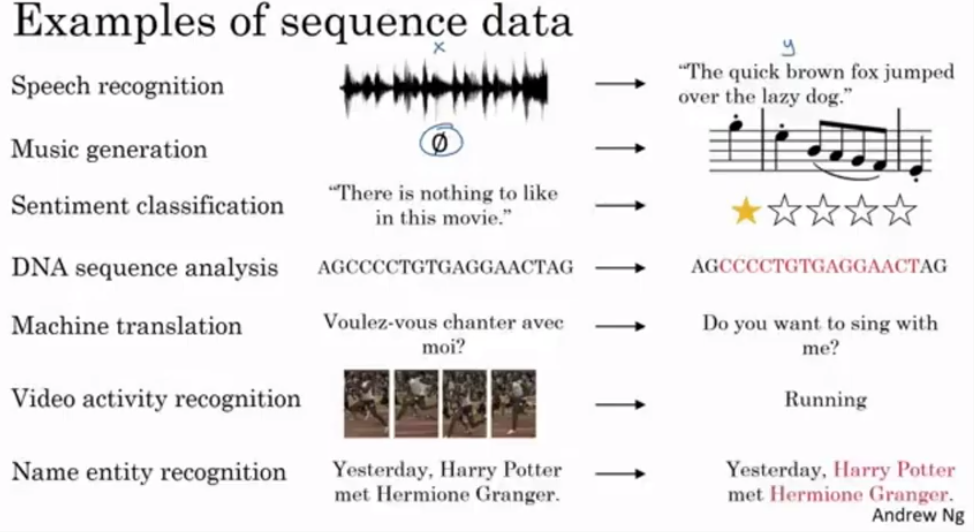
- NLP(Natural language processing)을 예시로 듬
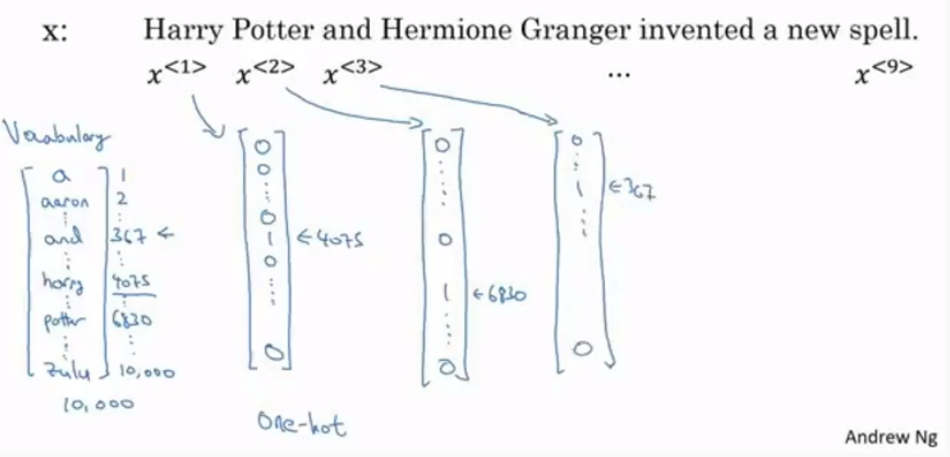
- 단어를 Dictionary를 통해 숫자로 매칭
- 원핫 인코딩 진행
알고리즘 제작방법
- 일반적인 네트워크로 만들수 없는 이유
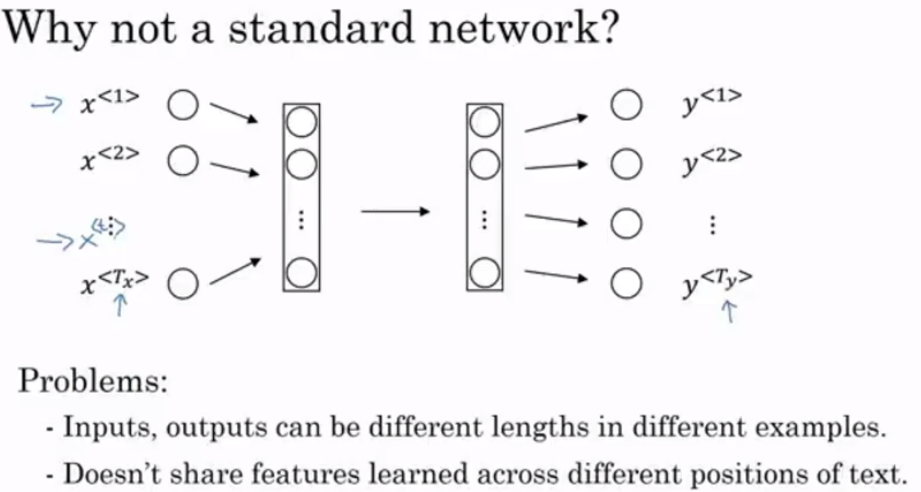 1) 다른 예시에 대해서 다른 길이를 갖고 잇음
2) 다른 위치에 대해서 특성을 공유하지 않음
1) 다른 예시에 대해서 다른 길이를 갖고 잇음
2) 다른 위치에 대해서 특성을 공유하지 않음
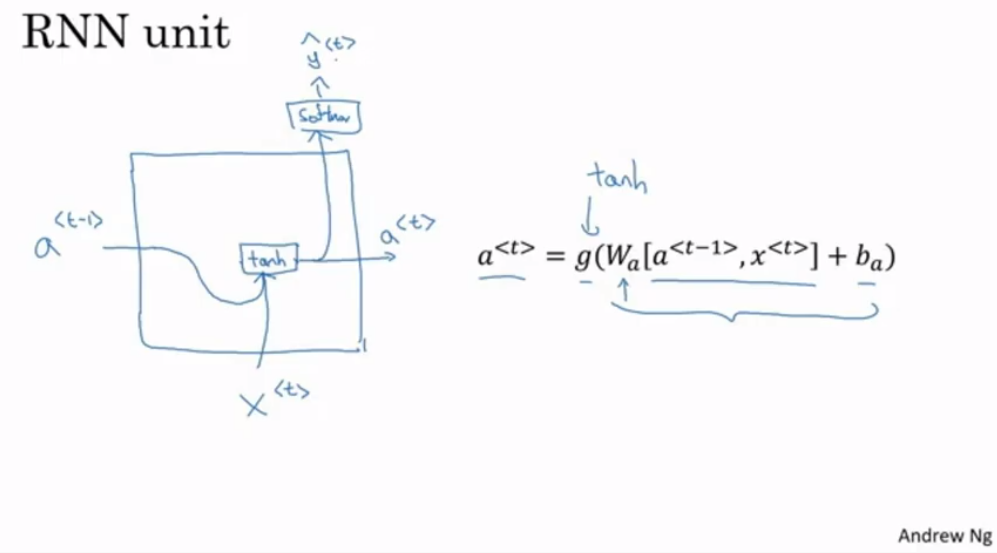
알고리즘 구조
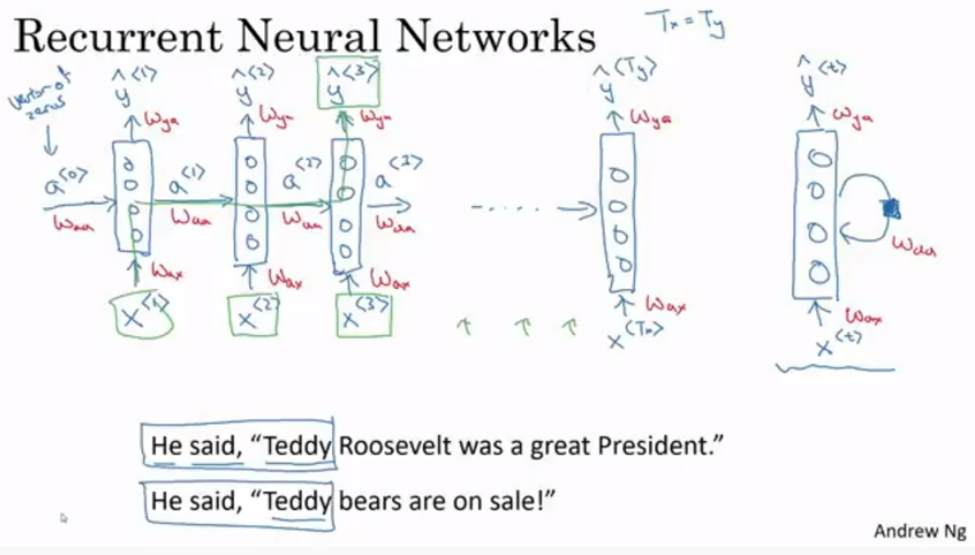
- 입력에서 은닉층 레이어로 가는 파라미터인 $W_ax$ 는 서로 같음
- 은닉층에서 다음 은닉층 레이어로 가는 파라미터인 $W_aa$ 는 서로 같음
- 은닉층에서 결과 레이어로 가는 파라미터인 $W_ya$ 는 서로 같음
- 문제점이 존재하는데 예시처럼 앞의 층만 봐서는 문장의 테디가 테이베언지 아니면 사람이름 테디인지 모른다는 것
- Forward Propagation” 구조는 다음 그림과 같음
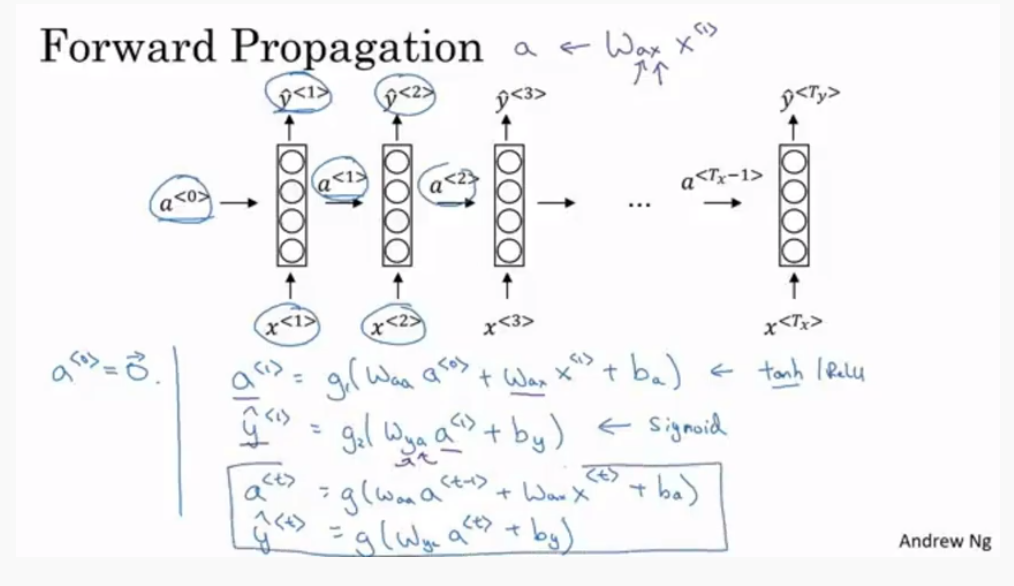
- activation은 tanh가 많이 사용되는데 이렇게 했을 때 생기는 vanishing gradient problem은 다음에 다룰 것
- 결과를 뽑는 activation은 결과의 형태 따라서 다르다. classification문제면 sigmoid 많이 사용
-
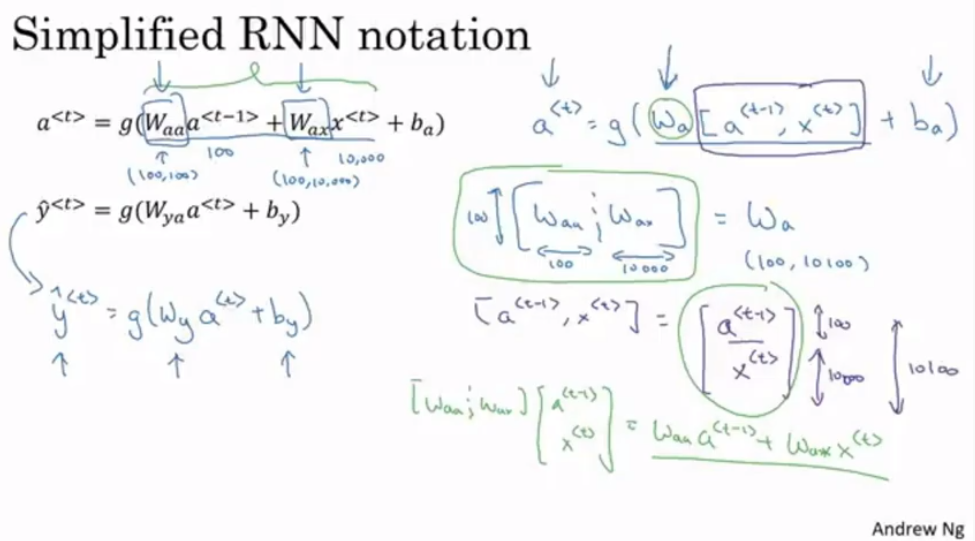
구조를 간단하게 고쳐보면 다음과 같이 변경하면 된다
- Back Propagation” 구조는 다음 그림과 같음
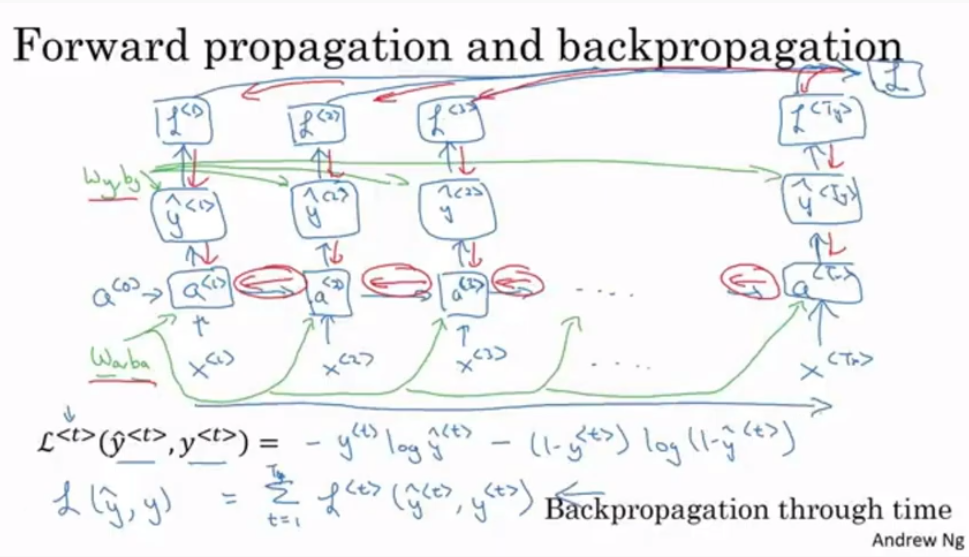
- 시간 흐르는 방향과 반대(왼쪽)로 역전파가 진행됨
RNN 구조의 종류
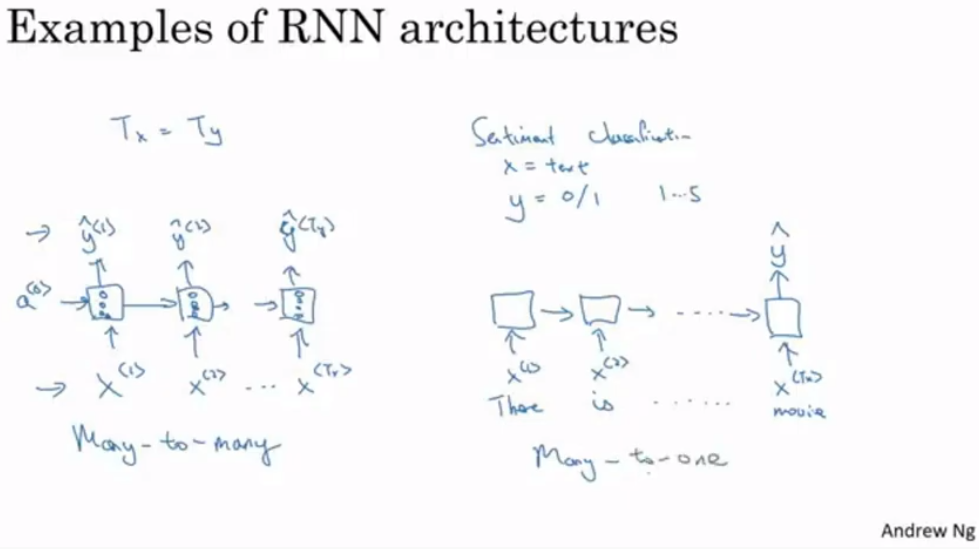
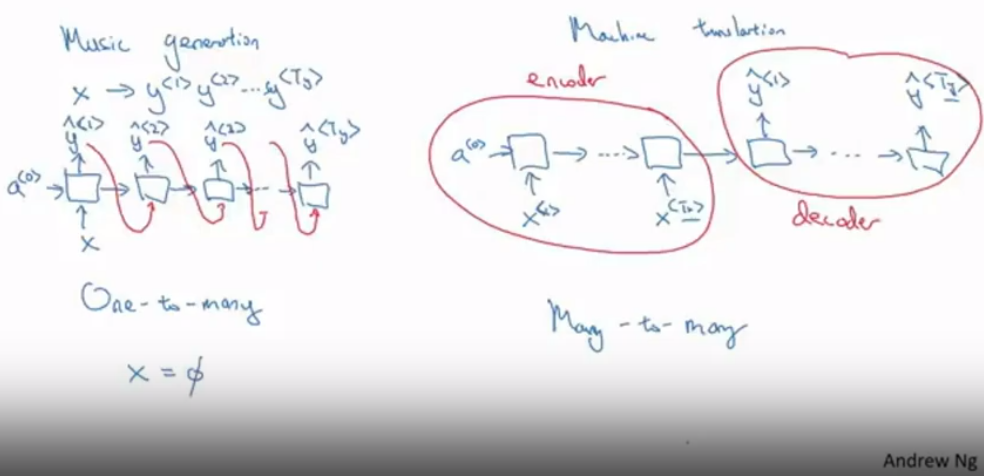
- Many-to-Many
- 입력 시퀀스와 나오는 시퀀스의 크기가 같음
- Many-to-One
- 결과가 하나만 나옴
- 분류같은 문제에 사용
- one-to-many
- 시퀀스를 만드는(Sequence generation)하는 알고리즘
- Music generation 등에 사용
- Many-to-many(시퀀스 길이가 다른 경우)
- 입력 시퀀스와 나오는 시퀀스의 길이가 다름
- 인코더, 디코더 구조
- Machine-translation 등에 사용
Language Generation
- Language modelling이란?
- Speech recognition
- P(sentence) 를 알려주는 것

- P(sentence) 를 알려주는 것
- EOS : 문장 끝을 알려주는 토큰
- UNK : 딕셔너리에 없는 단어를 표시하는 단어
- Speech recognition
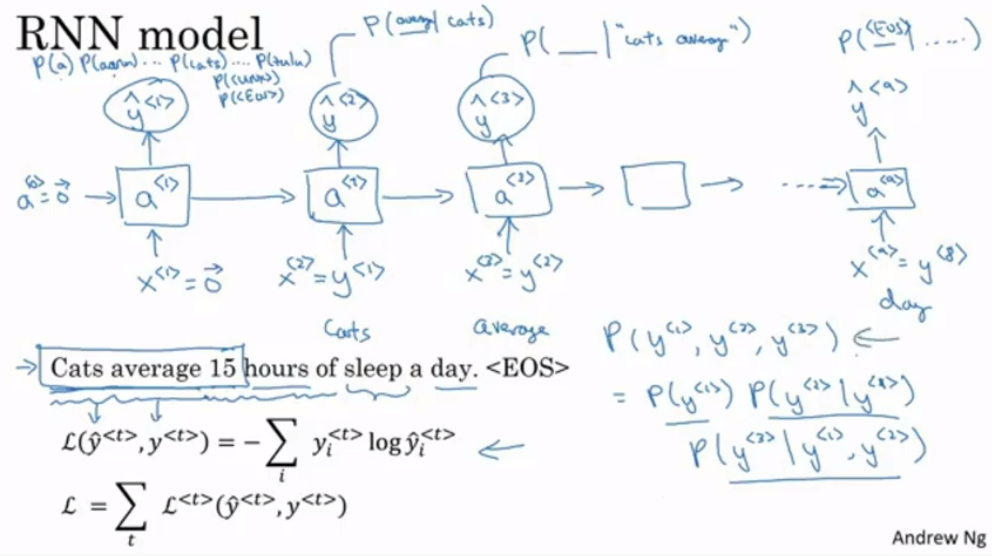
- 조건부 확률을 통해서 다음 단어를 예측하고 확률을 구함
새로운 시퀀스를 샘플링하는 것
- 샘플링 상황에서 훈련 때와는 다르게 획득된 새로운 입력을 다음 입력으로 넣는다
- 이때 전체 확률은 조건부 확률로 구해진다.
- EOS까지 계속한다.
- UNK 방지 방법으로는 UNK나오는 경우를 다 거부하고 계속해서 샘플링 진행하는 것이 있다.
- UNK가 나와도 상관없다면 계속해서 진행하는 것
Character-level language model
- 이전까지는 단어 단위로 했다면 알파벳 위주로 rnn을 짜는 것
- Space, 대문자, 기호 등을 포함해서 만들어야됨
- 시퀀스가 단어레벨보다 더 긴 것이 나옴
- 앞의 단어가 뒤의 단어에 영향을 주는 경우 성능이 좋지 않다는 단점이 존재함
- 계산량도 훨씬 더 많음 (expensive)
Gated Recurrent Unit(GRU)
-
기본 RNN 구조
- GRU 구조(간단히 한 구조)
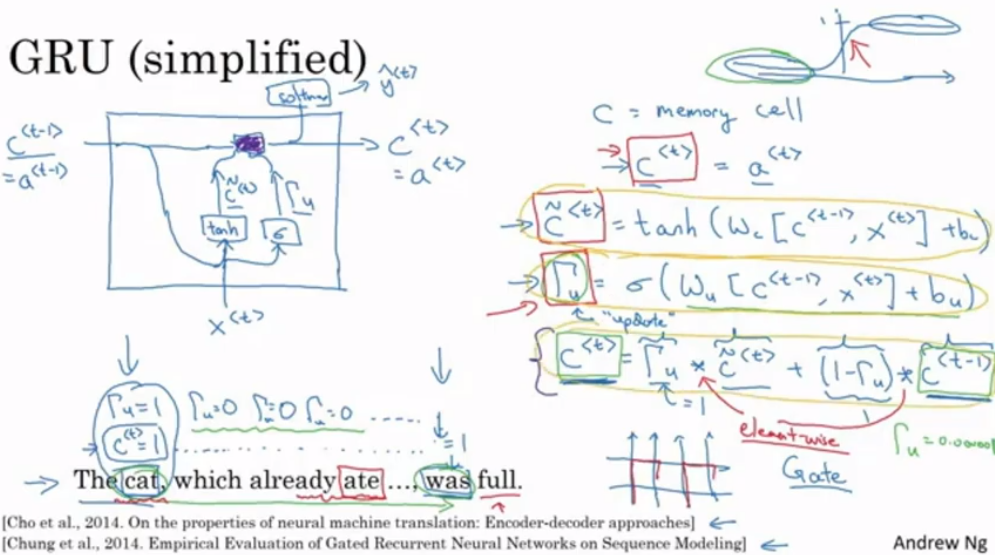
- C 는 현재 값을 기억하는 셀이며 (RNN의 Activation 값과 같음)
- $\Gamma$ 는 업데이트를 해야 하는지를 의미한다.
- 언어 생성할 때 앞의 주어의 단복수에 따라 뒤의 동사 형태가 형성되어야 함(앞 부분이 뒷 부분에 영향을 줌)
- 업데이트가 계속 안되어야지 현재 값을 보존해서 단수라는 것을
- Full GRU (실제 복잡한 구조)

- $\Gamma_r$은 다음 시점의 값과 이전 시점의 값과 얼마나 비슷한지를 나타낸다
- 대부분의 논문에는 이 감마들을 다 묶어서 쓰여있다(이해를 위해 나눠서 배운 것)
Vanishing Gradient 문제
- 일반적은 Neural network는 층을 지나면서 이러한 문제가 발생하는데 RNN은 sequence를 거치는 내에도 이 문제가 발생함
- 즉 앞의 input이 뒤에 영향을 주기 어려움
- Expanding gradient문제도 생길 수 있음. 값이 너무 커져서 Nan 값이 나오게 됨
- gradient clipping으로 값이 너무 커진 parameter를 rescaling하는 것
- 위 방식으로 Vanishing Gradient보다 문제를 쉽게 해결할 수 있음
LSTM(long short term meomry unit) 장단기 메모리 신경망
- GRU 처럼 긴 시퀀스의 정보를 기억함.
- Input gate, Forget gate, Output gate가 있음
- 그림의 빨간 색을 보면, 잘 파라미터 값들을 설정하기만 하면 맨 처음의 값이 계속해서 전달될 수 있는 것을 확인할 수 있다.
- Peephole connection(엿보기 구멍) : gate 값에 $C^{
}$도 참고하는 것 - GRU는 구조가 단순해서(게이트가 두개라) 큰 모델을 만드는 데 적합하며, LSTM은 보다 많은 게이트를 사용하고(게이트가 3개) GRU보다 이전 방식이라 더 잘 작동한다고 증명된 방식이다.
- 최근에는 GRU도 성능도 보장되면서 더 큰 네트워크를 만드는데 적합한 방식으로 인식되는 중
Bidirectional RNN
- 앞과 나중의 값에서 정보를 얻어오는 RNN
- 언어 구조에서 앞의 내용가지고만 뒤의 단어를 예측하면 다음과 같은 문제가 발생
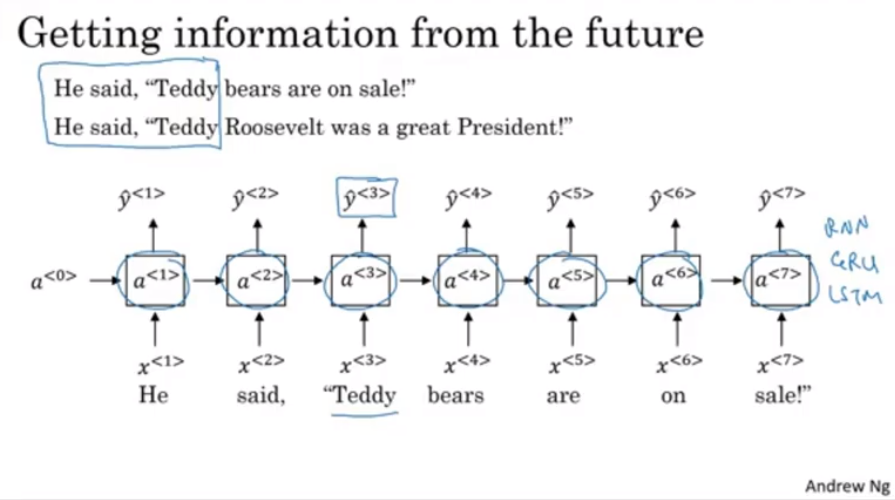
- 전체 구조는 다음과 같음(Acyclic)
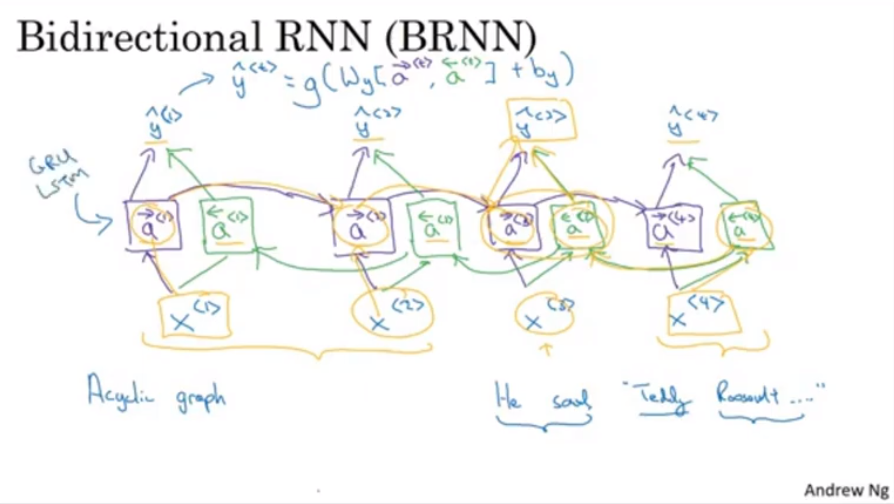
- 미래 정보와 과거 정보가 모두다 영향을 줌
- LSTM 블록으로 되어있는 BRNN이 NLP 문제에 많이 쓰임
- NLP 문장에서는 모든 sentence가 한번에 획득이 가능하기 때문이다.
Deep RNN
- RNN을 엮어서 더 Deeper하게 쌓는 것
- 3층 구조만 해도 Dimension이 엄청남
- 층의 일부만 더 깊게해서 다른 output을 뽑을 수 있음(파란 부분 참고)
- 마찬가지로 RNN, GRU, LSTM 층을 사용할 수 있음
Leave a comment