
cs230_lec5_C3W1
Updated:
(From : deeplearningai https://www.youtube.com/watch?time_continue=386&v=AwQHqWyHRpU)
모델 성능 높이는 법
- 데이터 더 모으기
- 더 다양한 데이터 수집하기
- 경사하강법 오래 사용
- Adam과 같은 최적화 방법 사용
- 더 큰 네트워크 사용
- 더 조그마한 네트워크 사용
- 드랍아웃 사용
- L2 정규화 사용
- 네트워크 구조 바꾸기
- 활성화 함수
- 은닉 노드 개수
- $\cdots$
시간 낭비하지 않고 이중에서 어떠한 방법을 택해야 할까…?
->!!앤드류 옹의 경험적인 전략 설명!!
직교화
-
TV tuning 예시
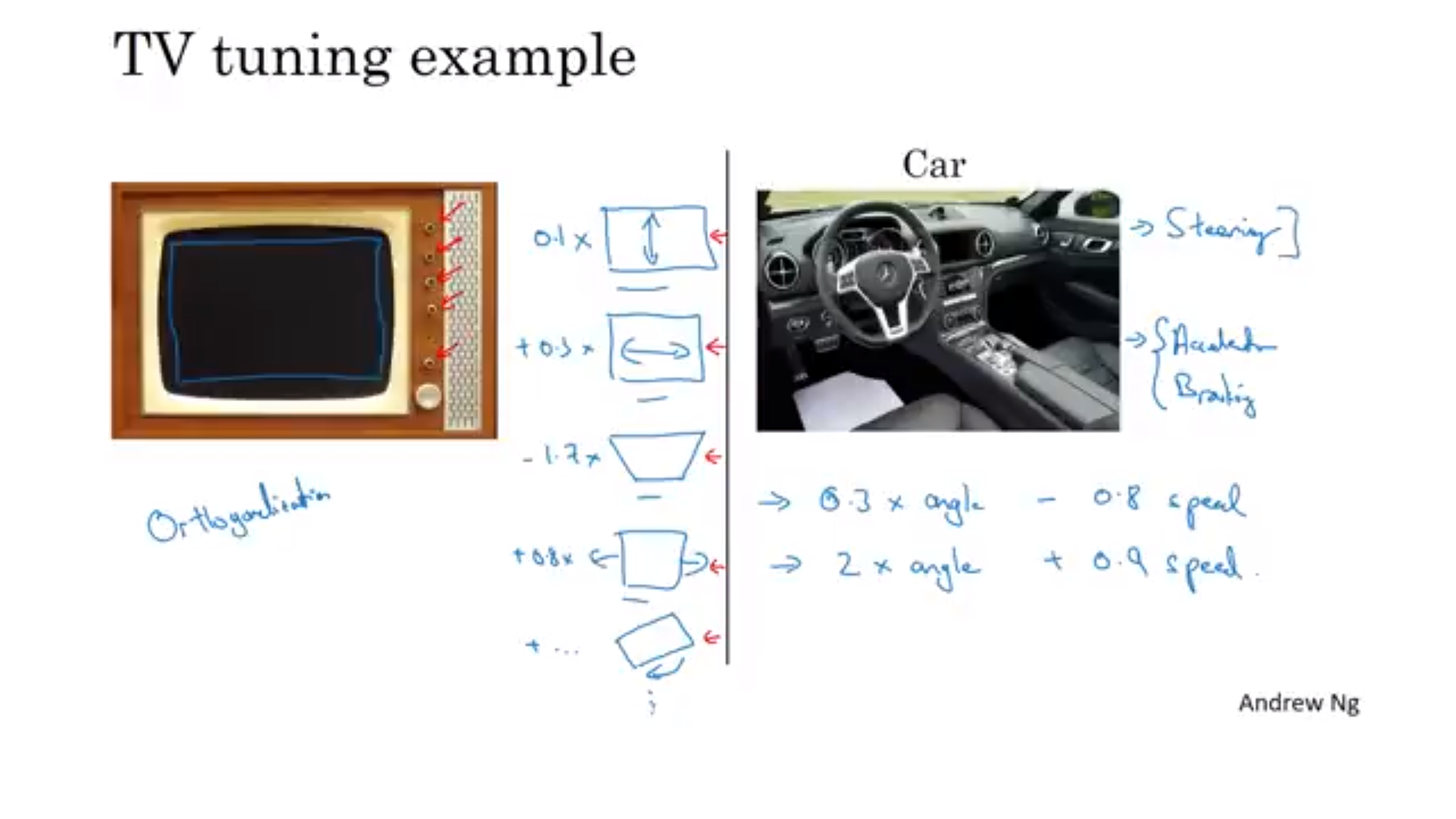
TV 디자이너가 버튼이 하나의 기능만을 맡도록 하는 것 - 머신러닝의 체인 가설
1 학습 세트에 대해서는 어느정도 성능을 보여야 한다(사람 수준과 비슷하게)
- 더 큰 신경망 사용
- 더 나은 최적화 알고리즘 사용 2 그 뒤 검증 셋에 잘 맞아야 하고
- 더 큰 학습 세트 사용
- 정규화 3 그 뒤 테스트 셋에 잘 맞아야 하고
- 더 큰 검증 셋 사용 4 그 뒤 실제 세상에 잘 맞아야 함 (Happy cat users)
- 검증 셋을 바꾸기
- 손실 함수를 변경하기
- 앤드류 옹은 earlystopping을 쓰지 않는데 training set, dev set 둘다 영향을 주기 때문임
- 기왕이면 한가지에 대해서 조절할 수 있는 직교화 된 방식들이 좋음
Single Number Evaluation Metric
- 알고리즘을 평가할 때의 실수 평가 기준!
- Precision
- 고양이라고 판단한 것 중에서 실제로 고양이인 것
- Recall
- 실제 고양이 사진중에서 몇개가 고양이로 인식되었는지
- 둘을 평가 기준으로 사용했을 때의 문제점은 두 상황의 두 평가 기준 값이 서로 다를 때 더 좋은 알고리즘 판단이 어렵다. (ex 95 90 vs 98 85 )
- 두개를 결합한 한개의 평가 기준이 필요
-
F1 score = 둘의 조화 평균 ( $\frac{2}{\frac{1}{P}+\frac{1}{R}}$)
- “검증 셋 + 하나의 실수 평가 기준” 을 가지면 빠르게 알고리즒 성능 평가가 가능
- 데이터에 따라 다른 성능을 보이는 알고리즘을 비교할 때 평균이 합리적인 평가 기준으로 판단되면 이를 사용하는 것도 좋음
Satisficing and optimizing metrics
-
예로 전체 평가 기준은 다음과 같이 설정 가능
Cost = accuracy - 0.5*running time
- 그렇지만 이렇게 선형으로 보통 설정하지는 않음
maximize accuracy
subject to running time $\leq$ 1000ms
-
음성인식 시스템을 예로 들면 음성인식 정확도도 높여야 하고 잘못 인식하는 경우 또한 줄여야 한다
Maximize accuracy
subject to false alarm $\leq$ 1
-
즉 정리하면 원하는 성능을 내고 싶은 조건을 Optimizing Metric으로 해서 성능을 최대로 높이되 다른 조건들은 Satysticing matric(조건 척도)로 설정하자는 것
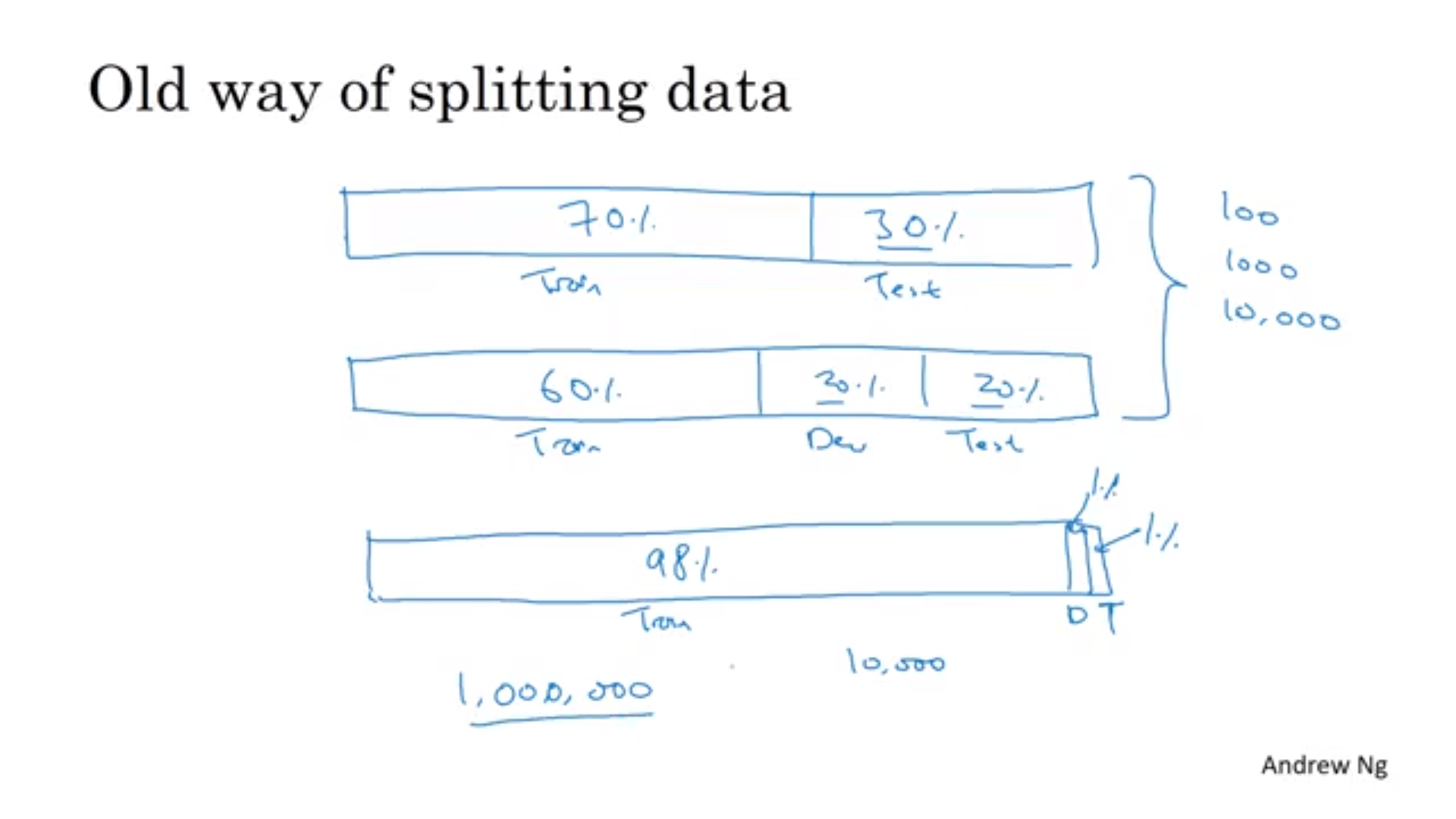
Train/Dev/Test set Distribution
- 설정 방법에 따라 학습 속도에 크게 영향을 줌
- 서로 다른 지역의 데이터를 Dev/Test로 나누면 지역마다 서로 다른 분포를 가지기 때문에 좋은 결과를 낼 수 없음
- 지역별 데이터를 무작위로 섞은 뒤 나누는 게 좋음
- 데이터 나누는 정도는 데이터 수에 따라서 다름
- 최근에는 데이터의 수가 많아짐으로써 대부분을 training set으로 사용가능
- 고양이 분류기
- 정확도가 높지만 야한 그림도 분류해버린다면? bad
- 평가 척도가 만족스럽지 않을 때 선호하는 척도를 택해라
-
여러 평가척도가 섞이게 된다면 직교화 방식처럼 각 척도에 잘 맞는 방식을 생각해라

- 테스트 데이터에 대해서는 평가 metric이 생각대로 맞지 않을 수도 있다(Input이 더 다양할 수 있기 때문)
- 테스트 데이터가 학습 데이터와 약간 다르다면 학습 데이터를 다르게 해서 학습해야 한다.
- 척도를 아무꺼나 잡고 진행하고 수정하고, 수정해라
사람의 성능과 비교하는 이유
- 사람과 경쟁 가능한 수준으로 알고리즘이 발전했기 때문
- 사람이 할 수 있는 것에 대한 미선 리넝 시스템을 디자인하고 만드는 것이 더 효율적이기 때문
- 알고리즘이 최대한 학습해도 이론적인 정확도의 한계인(Bayes error)를 뛰어넘지 못함
- 알고리즘의 정확도가 사람 수준을 넘어가게 되면 정확도가 시간이 흘러도 많이 증가하지는 못함
- 사람보다 성능이 안좋은 알고리즘은 성능향상을 쉽게 할 수 있음
- 사람들에게서 데이터의 라벨을 매기기
- 직접 데이터를 보고 왜 사람이 이렇게 판단했는지 확인
- 편향과 분산에 대해서 더 좋은 분석을 진행
Avoidable bias
- 사람 수준의 오차를 bayes error의 추정치로 여길 때의 방식
- 사람의 오차와 학습 & 검증 오차를 줄이는 것을 편향(bias) 줄이는 연구를 진행하는 것이다
- 학습오차와 검증 오차의 차이를 줄이는 것을 분산(variance)을 줄이는 것이다
- !!! 그림 넣어야 될듯
- 회피 가능 편향은 0.5%
- 사람 수준에 다다를수록 Avoidable bias와 Variance가 변화량이 크기 때문에 사람 수준 도달 이후에는 성능을 높이기 어렵다
- 정리하면 사람 수준의 error를 bayes error의 추정치로 이용하여 분사능ㄹ 줄일지 편향을 줄일 지 결정하는 것
사람 수준의 성능을 뛰어넘는 법
- training error가 사람의 error를 뛰어넘는 경우 분산, 편향중 어떤것을 줄여야 될 지 확정되지 않음
- 사람보다 성능이 뛰어난 case
- 온라인 광고 클릭
- 상품 추천
- 이동 시간 예측
- 대출 요청 승인
- 모든 위의 예시들이 Structure data로 학습됨
- 자연 인지 문제가 아님(Computer vision,speech recognition, natural perception X)
- 자연 인지 문제는 사람의 성능을 뛰어넘기는 어려움
- 자연 인지가 아닌 문제들도 최근 사람 개인의 성능을 넘어가고 있음(Speech recognition, some image recognition, Medical)
모델 성능 향상 가이드라인 (이전 내용 총 정리)
- 지도학습의 두가지 조건
- 학습 세트에 잘 맞아야 됨
- avoidable bias 작아야 함 -(더 큰 신경망 사용, 더 오래 학습) 2. 검증/테스트 세트에 잘맞아야 함
- variance 작아야 함
- (정규화, 더많은 데이터 사용)
- 알고리즘의 성능 향상을 최대한 하기 위해서는
- 베이즈 에러와 학습 에러의 차이를 구하기 (avoidable bias)
- 더 큰 모델 사용
- 더 오래 학습/ 더 좋은 최적화 알고리즘 사용
- 더나은 신경망 구조 사용(CNN, RNN)/ 하이퍼파라미터 search
- 학습 에러와 검증 에러 비교하기 (Variance)
- 더 많은 데이터 사용
- 정규화 진행
- 더 나은 신경망 구조 사용 / 하이퍼파라미터 search
- !! 그림 두종류 넣자!!
- 베이즈 에러와 학습 에러의 차이를 구하기 (avoidable bias)
Leave a comment