
cs230_lec2
Updated:
(From : Stanfordoline https://www.youtube.com/watch?time_continue=386&v=AwQHqWyHRpU)
Learning process
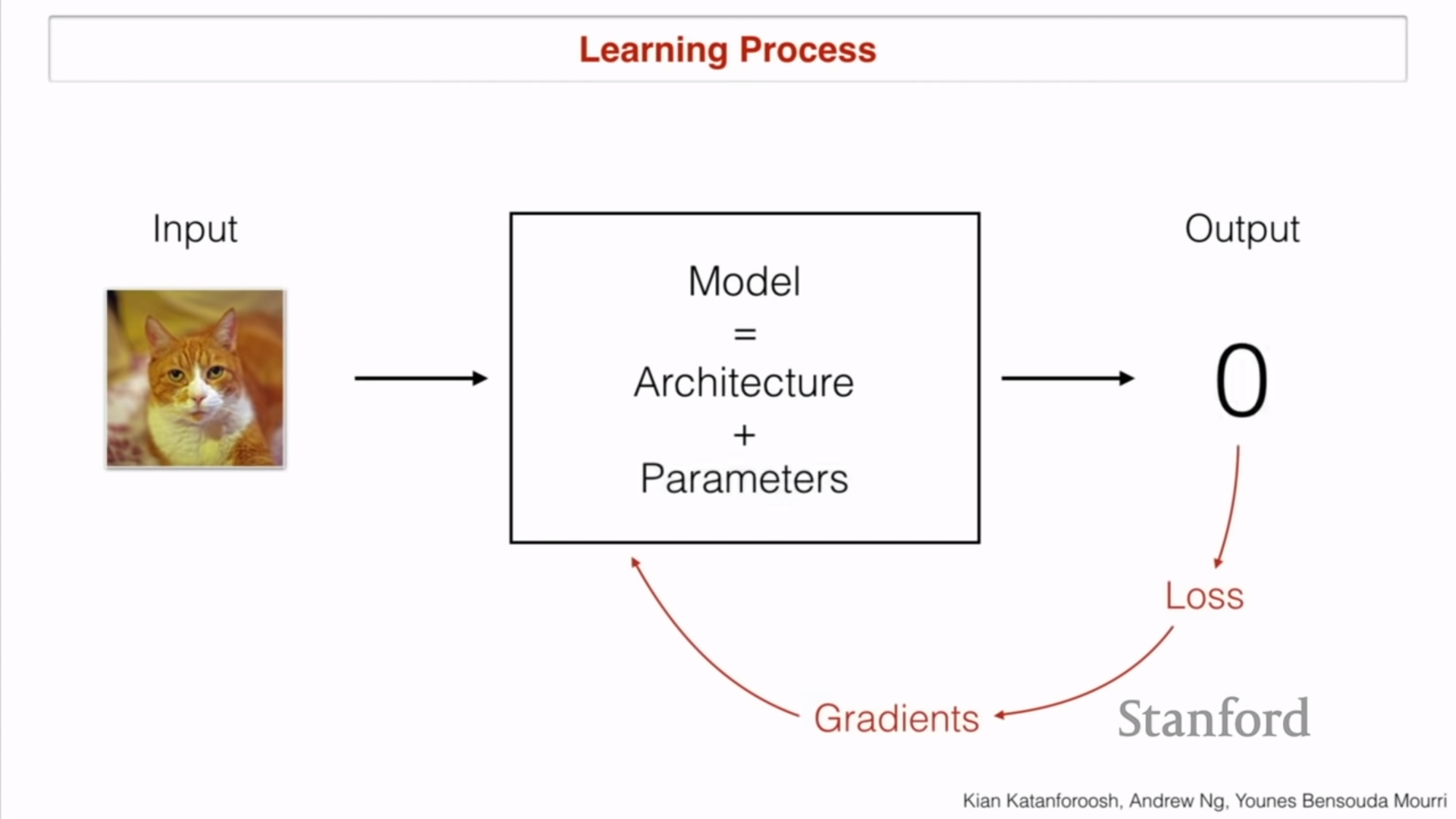
- Input과 Output은 우리의 목적에 따라서 설정
- Loss을 통해서 ground truth와 propataged output 사이를 비교
- 차이를 gradient로 하여 모델의 파라미터를 조정함
- Things that can change
- Activation function
- Optimizer
- Hyperparameters
Logistic regression
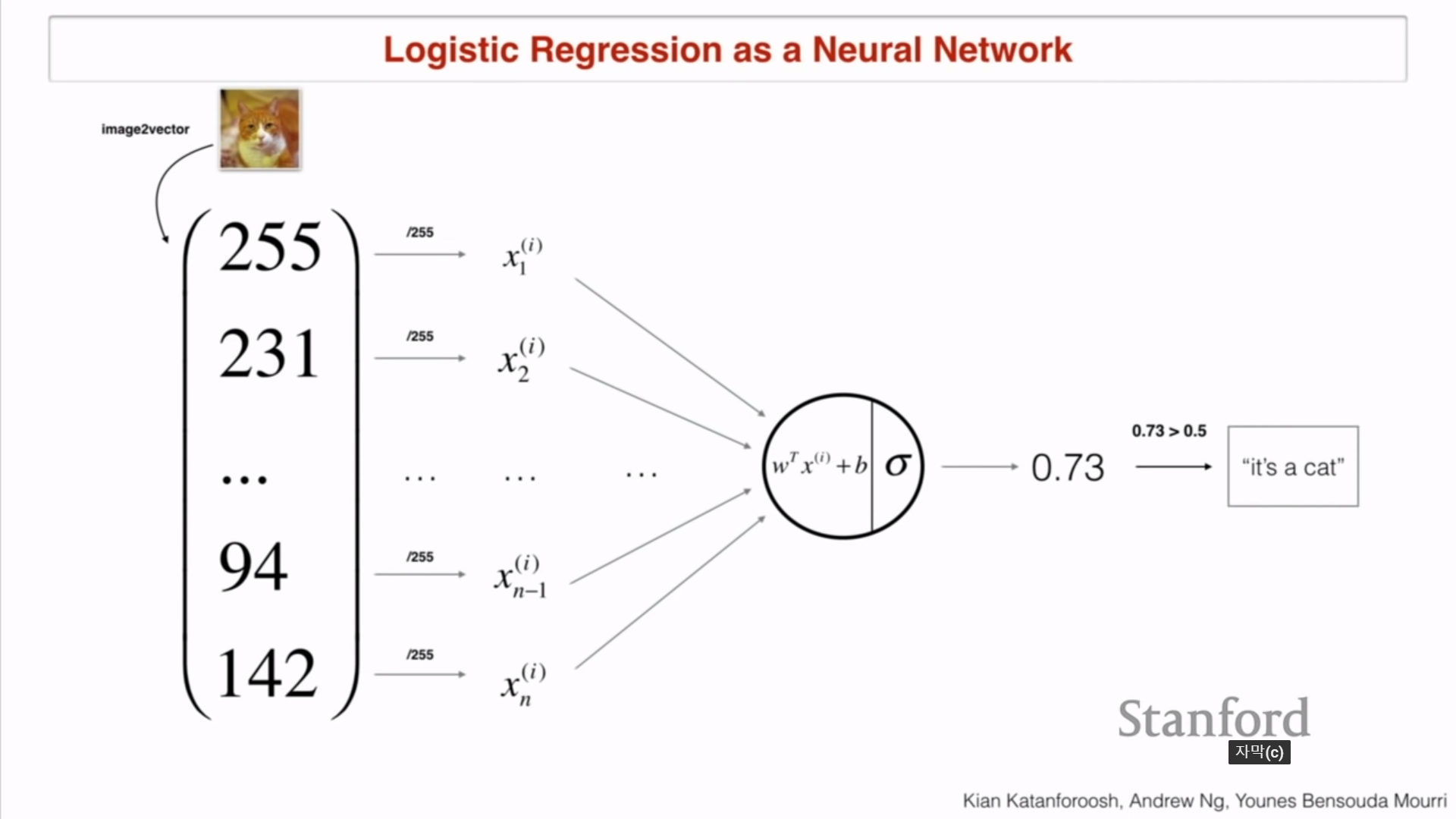
- 3D matrix (가로X세로Xrgb)로 이미지를 나타냄
- 0.5가 넘으면 고양이라고 판단함
- Q1 : 이미지가 들어왔을 때 고양이인지? 코끼리인지? 원숭이인지 아는 방법은?
- Multi Logistic regression model을 만드는 것
- Multi Logistic regression model을 만드는 것
- Q2 : 그럼 어떻게 어떤 neuron이 고양이를 나타내는지 코끼리를 나타내는지 아는가?
- Label를 달아주면 됨.
- Q3 : 그럼 라벨링은 어떻게 할까?
- One hot encoding vector ex) (1, 0 , 0 , 0 )
- Q4 : One hot encoding의 단점은?
- 코끼리와 고양이가 동시에 나오는 그림은 판단 못함
- Multi-hot encoding 필요 ex) (1, 1, 0, 0)
- One-hot encoding은 사진에 동물이 1개밖에 없다는 constraint가 있을 때 잘 작동
- 이때는 activation function을 sigmoid대신에 softmax를 사용해야됨
Deeper networks
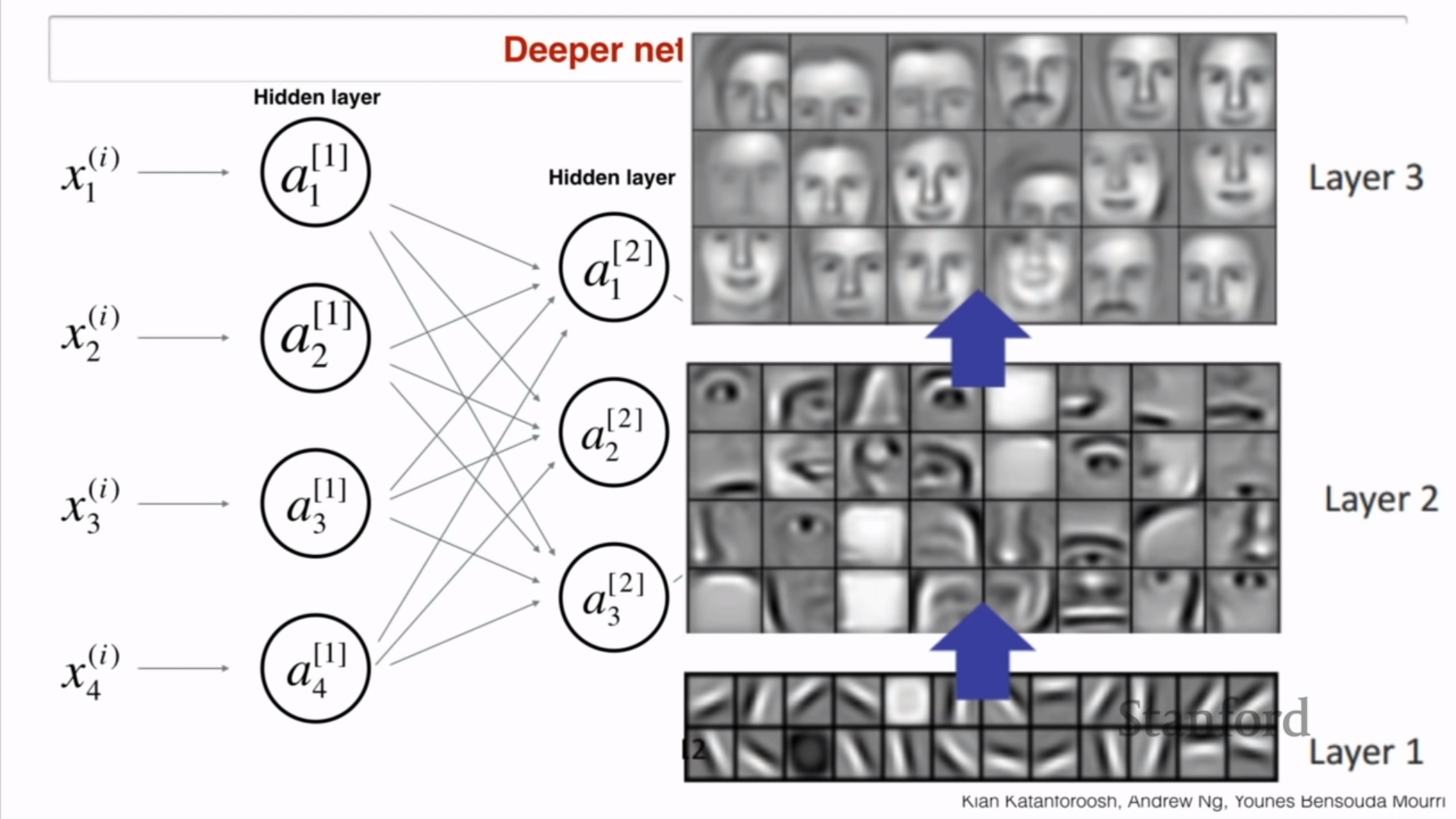
- 레이어의 층수가 더 높아질 수록 더 고차원의 복잡한 정보을 저장함
- 이것들이 encoding 으로 불림
- encoding : 데이터를 추출하여 어떠한 숫자로 변환하여 짝지어 놓은 것
- 낮은 level의 특성은 높고 복잡한 level의 특성으로 encoding됨
Today’s outline

1) Day’n’Night classification (Classification problem)
- 낮과 밤의 image 필요
- Q1 : 필요한 이미지의 개수는?
- 먼저 complexity of the task를 결정해야됨
- 이 문제는 Cat 구분 problem과 비교했을 때 더 쉬움. 즉 데이터가 적게 필요
- 그러나 Dawn, twilight, sunlight 이미지를 구분 학습할 것인지 결정하는 것과, 집 안에서 창문이 있는 이미지면 task가 어려워짐
- 데이터의 개수는 경험에 의해서 결정됨
- Q1+ : 학습/테스트 데이터 비율을 어떻게 나눌 것인가?
- 데이터의 개수가 많을 수록 학습 비율을 증가시키고 테스트의 비율을 감소시켜도 됨
- Q2 : Resolution(해상도)은 왜 신경써야되는가?
- 저해상도면 계산이 쉽기 때문
- Q2+ : 해상도를 얼마나 낮출지 어떻게 결정하는가?
- 사람의 performance와 비교(이미지 64643)
- Task의 난의도에 따라서 달라질 수 있음.
- Q3 : Output?
- y=0, y=1
- Q3+ : Last Activation function?
- sigmoid
- Q4 : 구조
- 어렵지 않으니 shallow network도 쉽게 할 수 있음
- Q5 : Loss?
- Maximum log likelihood
- $L=-[y log(\hat{y})+(1-y) log(1-\hat{y})]$ -> Convex function, easy to optimize.<Check cs229>
2) Face Verification (Face-Id mapping)
- Q1 : Data
- 이름이 적혀 있는 학생들의 사진
- Q2 : Input?
- 출입하고자 하는 카메라에서 찍은사진
- Q2+ : 해상도는?
- (4124123)
- 밤, 낮 구분과 비교해서 어려운 task이기 때문
- Q3 : Output ?
- y=1 (it is you), y=0 (not you)
- Q4 : 구조
- 그림간의 픽셀 거리 비교
- Q4+ : 발생하는 문제들
- 배경 빛 차이, 외형변화(ex 수염), 오래된 사진
- 벡터안의 사진에 정보(눈, 코 입, 머리 등등)을 인코딩해야됨

- Q5 : Loss? Training?
- 1 million image를 online으로 학습해서 face recognition에서 어떤 특성을 학습해야 되는지 알아내기
- Q5+ : 왜 고양이 문제처럼 one-hot encoding 못하는가?
- 학생들이 매년 바뀌기 때문에 네트워크를 바꿔야 하기 때문
3) Face Recognition (no ID)
- (1) 목표 : 학교 시설에 출입가능한 학생인지 확인
- Verification때는 해당되는 사람과 one-to-one 비교를 하지만, Recognition에서는 one-to-N 비교를 통해 알아냄(1대1 비교에는 시간이 많이 걸리므로)
- 검증하고자 하는 얼굴을 알고리즘에 집어 넣은 뒤 벡터를 뽑아낸 뒤, 모든 사람들의 얼굴을 알고리즘에 넣어서 출력된 데이터베이스의 벡터들과 비교해서 알아냄.
- Complexity : Number of students
- K-Nearest Neighbors 사용 가능.
- (2) 목표 : 핸드폰에 저장해 놓은 사람들과 단체사진에서 Face clustering을 진행함
- K-Means Algorithm
- Q : K 값을 정하는 방법은?
- X-means, Elbow method 등등
- 값들을 넣어보면서 성능빙교
4) Art generation (Neural Style Transfer)
- (1) 목표 : 주어진 사진을 더 이쁘게 바꾸기
- Q1 : Data?
- 어떤거든 사용해보기
- Q2 : Input?
- Content Image(이쁘게 할 사진)
- Style Image(이쁜 그림)
- Q3 : Output?
- Generated Image(이쁘게 할 사진과 이쁜 그림을 합친 것)
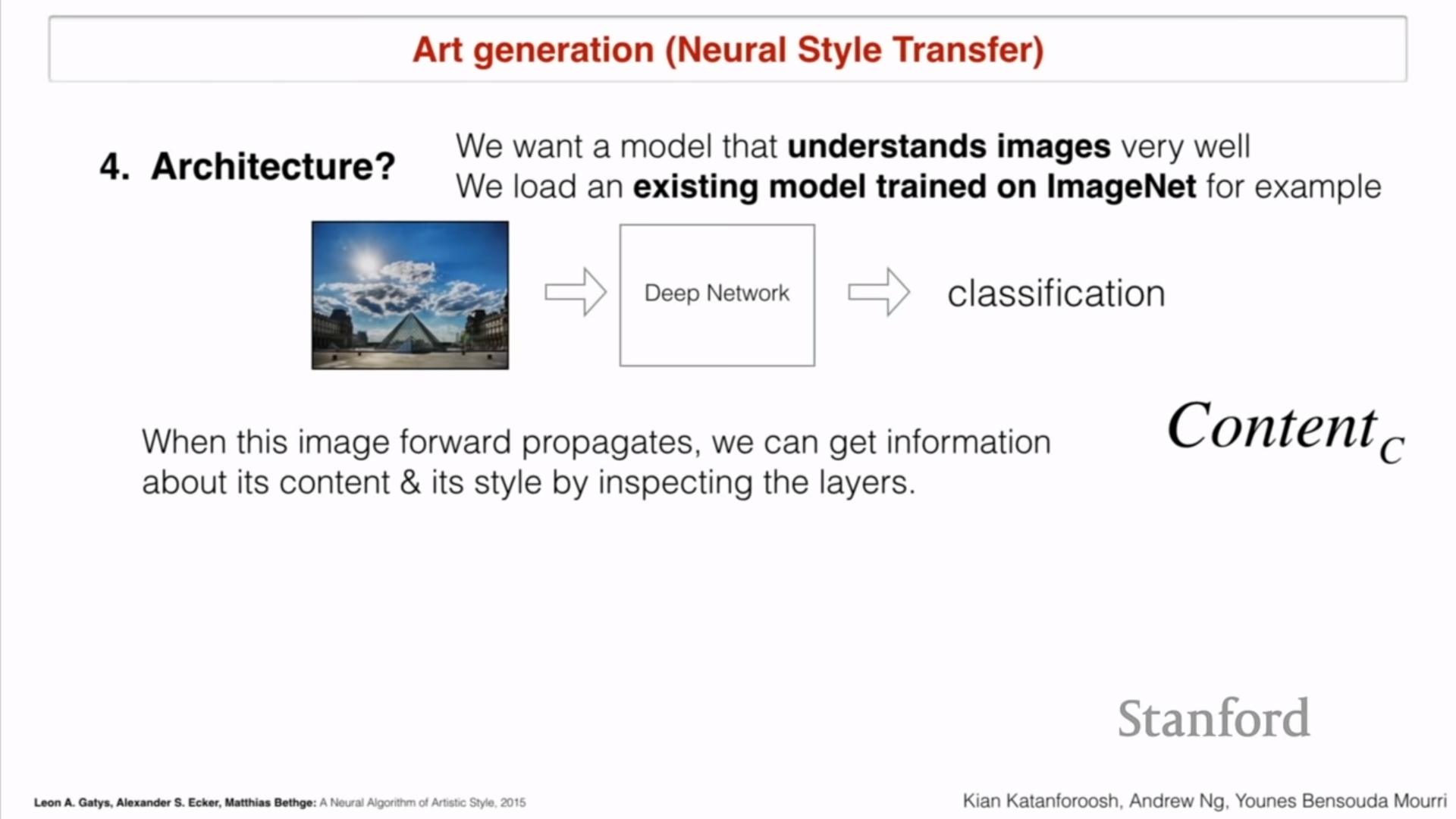
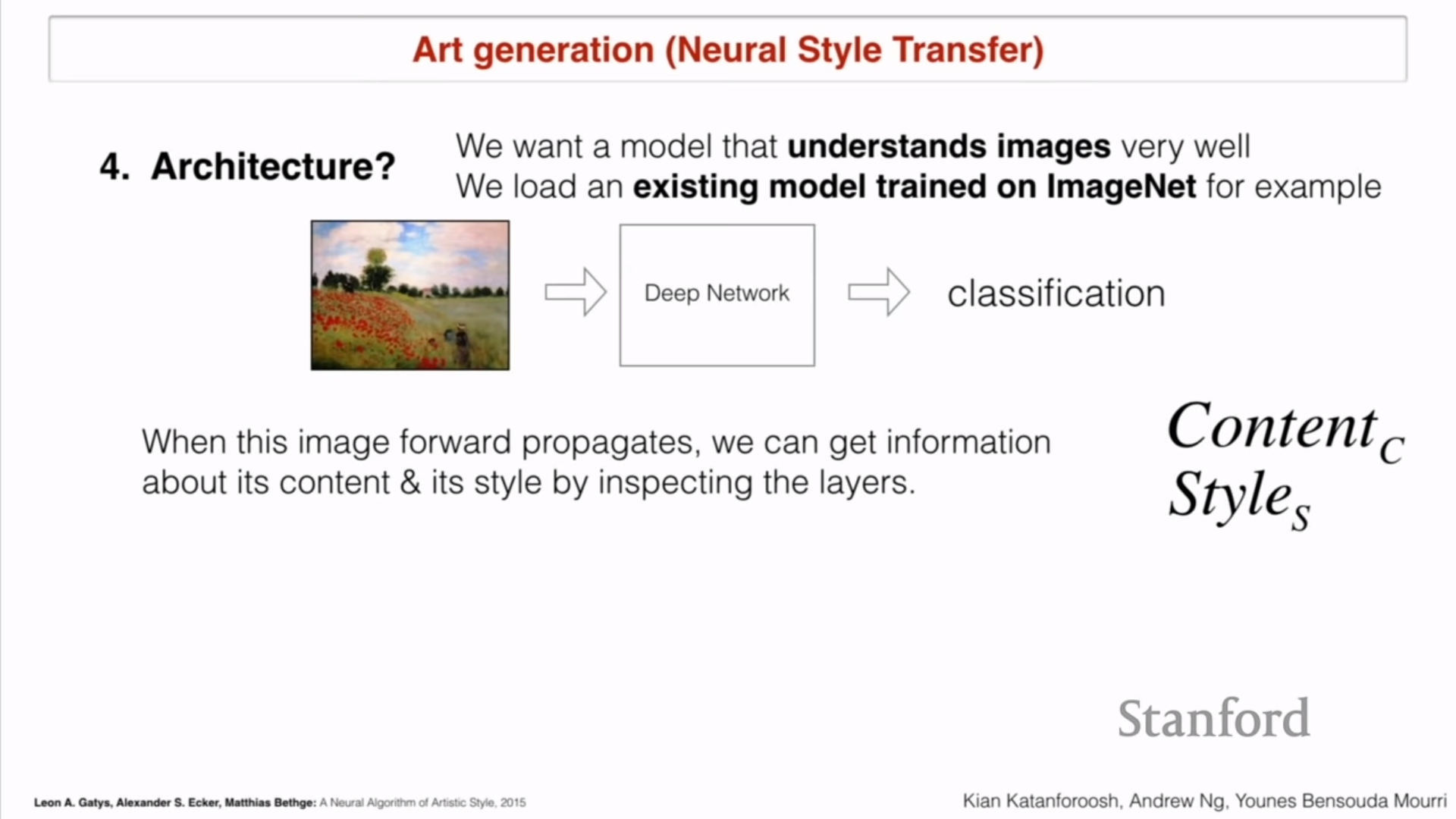
- Q4 : Architecture
- 이미지를 잘 이해하는 모델을 세운다
- ImageNet에 있는 기존 모델을 불러온다
- 기존 이미지로 $Content_c$(content of content image) 뽑아내고
- Style 이미지로 $Style_S$(Style of Style image)) 뽑기
- Q4+ : ImageNet을 사용해야 하는 이유는?
- 이미지넷이 우리의 그림을 인식할 수 있기 때문!
- 이미지넷의 classification output이 필요한 것이 아니라 edges 등등의 이미지의 특성을 잘 학습할 수 있는 네트워크 부분이 필요한 것!
- Q5 : Loss?
-
$K= Content_C-Content_G _2^2+ Style_S-Style_G _2^2$ - 둘다 최소화해야 되기 때문에
-
- 올바른 방법
- Loss 를 줄이면서 파라미터를 배우는 것이 아님. 우리는 이미지를 학습하는 것!
- Training loop을 거쳐야됨
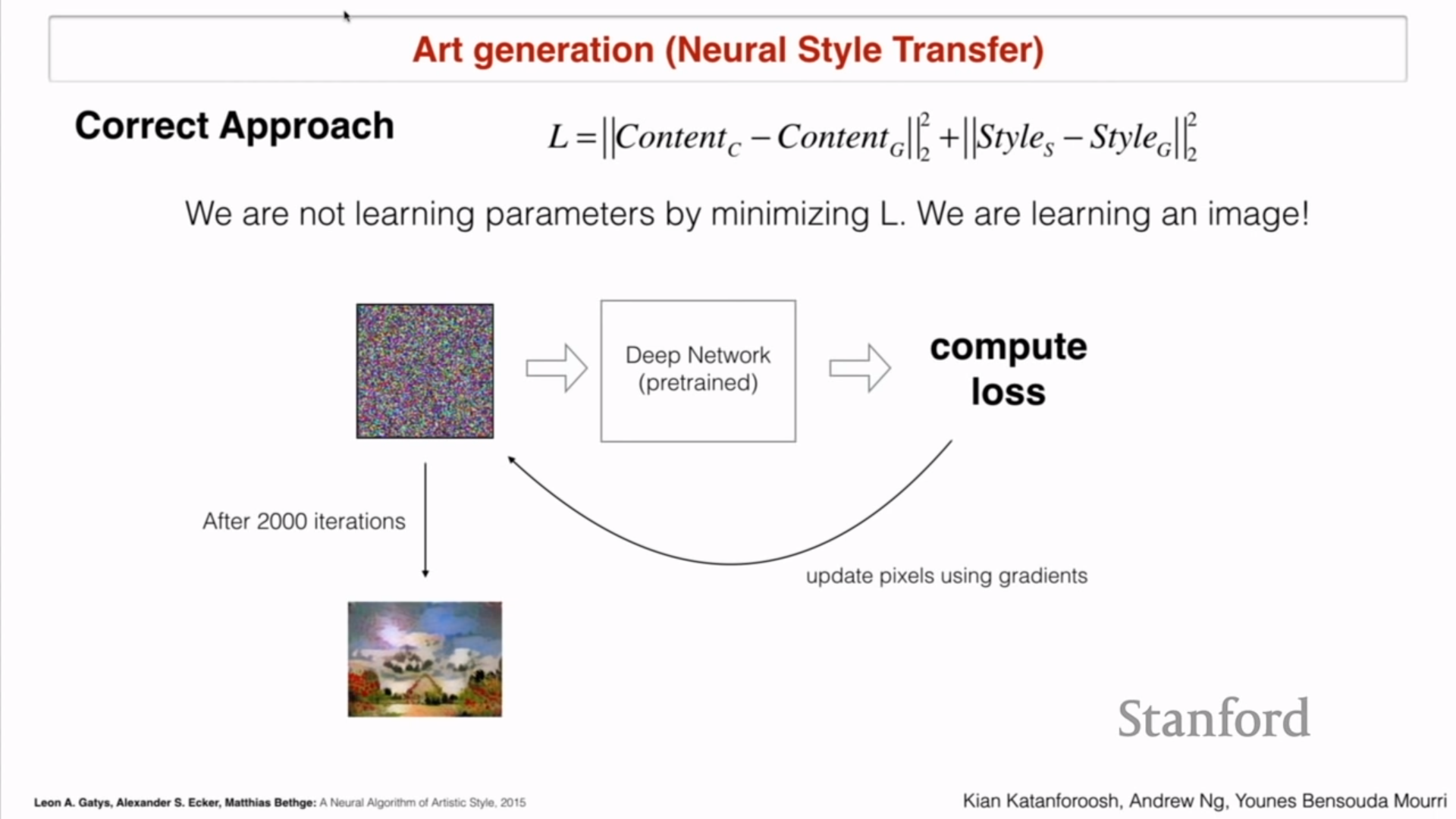
- White noise로 시작해도 되지만 edge를 잘 학습할 수 있게 contents부터 시작해도 됨
- Q1 : Data?
5) Trigger word detection
- (1) In 10sec audio speech, Detect the word “activate”
- Q1 : Data
- 10초 단위의 오디오 클립
- Q1+ : Distribution
- 악센트, 남녀 아이 목소리 최대한 많이 포함
- Q2 : Input
- activate, not activate 표시되어 있는 10sec 오디오 클립
- Q2+ : 해상도(Resoultion)?
- 사람에 대한 Test로 결정, 전문가의 결정
- Q3 : Output
- y=0, y=1 -> y=0000 … 00100 y=0000 … 001.. 100
- Q3+ : Sigmoid (Sequential)
- Q4 :Architecture?
- RNN
- Q5 : Loss?
- $L=-[y log(\hat{y})+(1-y) log(1-\hat{y})]$
- Q1 : Data
- Task를 성공적으로 끝내기 위해 필요하 것
- (1) Strategic collection of data
방법 1
- 캠퍼스에서 녹음기 틀고 돌아다니기
- Labeling: 사람이 직접 하면 오래걸림, 영화 자막 사용하기 방법 2
- 1-1 Positive word
- 1-2 Negative word
- 1-3 Background noise
- 자동으로 라벨링하기
- (2) Architecture serach & Hyperparameter tuning

- (1) Strategic collection of data
방법 1
- 쉬어가기
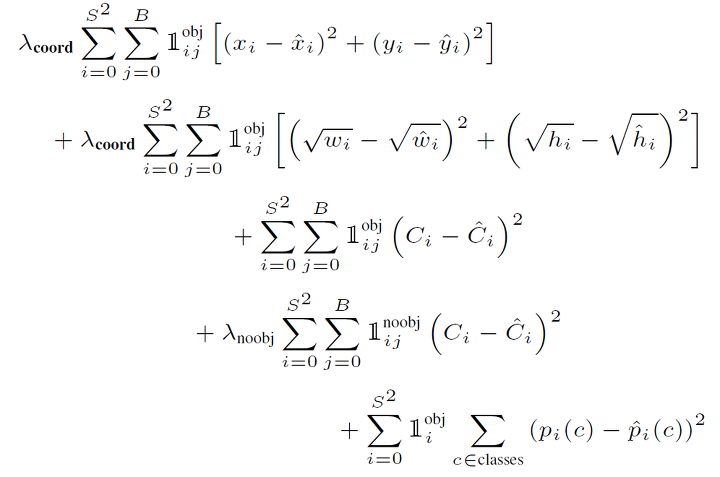
- YOLO : Bounded box object Detection Loss function
- 첫째항 : 중앙 위치
- 둘째항 :폭, 너비 (큰 박스의 차이보다 조그마한 박스의 차이가 더 중요하기 때문에 square root를 한 것)
- 샛째항 : 물체가 많으면 Objectness 크다 -넷째항 : 물체가 없으면 Objectness 작다
- 마지막항 : 물체 종류 분류
- YOLO : Bounded box object Detection Loss function
Leave a comment